Design
How to design a deidentifier? And how to verify that it does what you designed it to do?
Aims
Why do we need medical image deidentification? Deidentification is one of the available methods to achieve two goals:
To make the data inside a medical image available
To Protect patient confidentiality
Other methods can be used instead of or in addition to deidentification. Restricting access, contracts, aggregating data are all valid approaches. For a full discussion of methods, reasoning and legal underpinning, see the European Data Protection Board guidelines on Pseudonymization.
Note
MIDOM focuses on deidentification of medical image data in the european context. Firstly, “patient confidentiality” is understood to be based on the EU’s GDPR regulation. Secondly, alternative methods of protecting patient confidentiality, though important, are kept out of scope here.
Split actions from implementation
How to create a script or program to remove patient information from medical image files? The most direct way is to find code to modify the image file, set rules to modify the elements you want, and done.
This approach runs into problems. The crux of the problem is that image deidentification contains both technical and policy elements. Implementation can be complex and highly technical At the same time, the general approach should be based on policy decisions and reviewable.
The solution proposed by MIDOM is to separate the definition into two concepts. A protocol describes deidentification approach in terms of actions. A deidentifier is a specific implementation of the rules set out in a protocol.
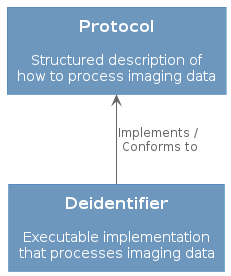
Deidentification definition is split between general rules (Protocol) and concrete implementation (Deidentifier)
One Protocol can be implemented in multiple ways, on different platforms.
Context of use is essential
One of the most important elements of EU pseudonymization guidelines is the concept of the pseudonymization domain, defined as
the context in which pseudonymisation is to preclude attribution of data to specific data subjects
In MIDOM, any protocol is *only considered appropriate for a given domain.

A Protocol is only appropriate for a given domain
Validation
Once you have decided on a protocol, and implemented a deidentifier based on it, how do you make sure it does what you want?
The basic approach is to collect DICOM dataset examples from the Domain. Each example is then connected to a desired output which together are a Validation Set. Each example in a Validation Set can then be compared to the output of the deidentifier.
Validation Set
A collection of medical image examples with reference output.
The DICOM dataset examples are collected together in a Region Sample Set. For each of the DICOM datasets in the region sample set, the desired output is registered in a Deidentification Reference. Multiple region sample sets can be included in this way. All the sample sets and references together form a Validation Set.
A validation set describes what is considered ‘correct’ deidentification for a certain Domain. Defining a validation set is as much a policy decision as it is a technical one.
![@startuml
!include https://raw.githubusercontent.com/plantuml-stdlib/C4-PlantUML/master/C4_Container.puml
!define osaPuml https://raw.githubusercontent.com/Crashedmind/PlantUML-opensecurityarchitecture2-icons/master
!include osaPuml/Common.puml
!include osaPuml/User/all.puml
!include <office/Servers/database_server>
!include <office/Servers/file_server>
!include <office/Servers/application_server>
!include <office/Concepts/service_application>
!include <office/Concepts/firewall>
'# remove <<system>> above each block
HIDE_STEREOTYPE()
Container(domain, "Domain", "", "The type(s) of data and the context in which it is used") #6E97BE
Boundary(validation_set, "Validation Set") {
Container(region_sample_set, "Region Sample Set", "", "| ds_A |\n| ds_B |\n| ... |") #6E97BE
Container(region_sample_set2, "Region Sample Set", "", "| ds_C |\n| ds_D |\n| ... |") #6E97BE
Container(region_sample_set3, "Region Sample Set", "", "| ds_E |\n| ds_F |\n| ds_G |\n| ... |") #6E97BE
Container(deidentification_reference, "Deidentification Reference", "", "Shows desired\nprocessing result\n\n| ds_A | -> ds_A` |\n| ds_B | -> ds_B` |\n| ds_C | -> ds_C` |\n| ds_D | -> ds_D` |\n| ds_E | -> Reject |\n| ds_F | -> Reject |\n| ... | ... |")
region_sample_set <-r- deidentification_reference : "contains"
region_sample_set2 <-r- deidentification_reference : "contains"
region_sample_set3 <-r- deidentification_reference : "contains"
region_sample_set -[hidden]-> region_sample_set2
region_sample_set2 -[hidden]-> region_sample_set3
}
domain <-[dotted]- region_sample_set : "Samples"
domain <-[dotted]- region_sample_set2 : "Samples"
domain <-[dotted]- region_sample_set3 : "Samples"
@enduml](_images/plantuml-96fcc6e9668463f3aaae8b46d1032773b2f16a45.png)
A Validation Set consists of multiple region sample sets and their desired output. Desired output is always defined in the context of a Domain.
Overview
To protect patient confidentiality in certain Domain, A protocol is defined. A deidentifier is then created that implements this protocol.
To validate the deidentifier, examples and reference output are collected in a Validation Set. Reference output can only be considered correct in the context of a certain Domain
![@startuml
!include https://raw.githubusercontent.com/plantuml-stdlib/C4-PlantUML/master/C4_Container.puml
!define osaPuml https://raw.githubusercontent.com/Crashedmind/PlantUML-opensecurityarchitecture2-icons/master
!include osaPuml/Common.puml
!include osaPuml/User/all.puml
!include <office/Servers/database_server>
!include <office/Servers/file_server>
!include <office/Servers/application_server>
!include <office/Concepts/service_application>
!include <office/Concepts/firewall>
'# remove <<system>> above each block
HIDE_STEREOTYPE()
Container(domain, "Domain", "", "The type(s) of data and the context in which it is used") #6E97BE
Container(protocol, "Protocol", "", "Structured description of how to process imaging data") #6E97BE
Container(deidentifier, "Deidentifier", "", "Executable implementation that processes imaging data") #6E97BE
Boundary(validation_set, "Validation Set") {
Container(region_sample_set, "Region Sample Set", "", "| ds_A |\n| ds_B |\n| ... |") #6E97BE
Container(region_sample_set2, "Region Sample Set", "", "| ds_C |\n| ds_D |\n| ... |") #6E97BE
Container(region_sample_set3, "Region Sample Set", "", "| ds_E |\n| ds_F |\n| ds_G |\n| ... |") #6E97BE
Container(deidentification_reference, "Deidentification Reference", "", "Shows desired\nprocessing result\n\n| ds_A | -> ds_A` |\n| ds_B | -> ds_B` |\n| ds_C | -> ds_C` |\n| ds_D | -> ds_D` |\n| ds_E | -> Reject |\n| ds_F | -> Reject |\n| ... | ... |")
region_sample_set -r-> deidentification_reference
region_sample_set2 -r-> deidentification_reference
region_sample_set3 -r-> deidentification_reference
region_sample_set -[hidden]-> region_sample_set2
region_sample_set2 -[hidden]-> region_sample_set3
}
domain <-> protocol : "Policy decision:\nA protocol is suitable for"
deidentifier -> protocol : Implements /\n Conforms to
protocol -[hidden]-> deidentifier
validation_set -> protocol : Exemplifies the processing described by
validation_set -d-> deidentifier : Can directly validate conformance of
validation_set -u-> domain : Shows 'correct' deidentification for a domain
@enduml](_images/plantuml-8fe119b8e76b974a76108a371fbde57122a0ec7d.png)
Objects used in the validation of a deidentifier.
Domain
The context in which a deidentifier or protocol is meant to help protect patient confidentiality. See Context of use is essential
In MIDOM, the concept domain is used in two related by separate ways:
- Domain in a broad sense
A Domain in a broader sense refers to “The entire context in which a deidentifier functions”. This includes policy and organizational aspects, contracts, training, cyber security. This sense of ‘domain’ is the one used in the GDPR. It is the sense used in the sentence “A protocol is suitable for this domain”.
- Domain in a narrow sense
When talking about region sample sets, ‘domain’ means “All possible DICOM datasets” that a deidentifier is expected to handle”. Technically, it is a region in Dataset Space and does not include any organizational elements.
Region Sample Set
A distinct region of Dataset Space that the deidentifier is expected to work in. The grouping is not strictly defined, but described in free text. For example “Standard DICOM datasets”, “Complicated Ultrasound images”, “Images used in hospital X” or “Samples of studies encountered in project Y”
Deidentification Reference
The desired output for the examples in a region sample sets. Valid only int he context of a Domain.
Desired output for a single example can be one of two types:
A (transformed) dataset - This indicates the ‘correct’ deidentification of this dataset in the context of the domain
Reject - The input dataset is supposed to be rejected by the deidentifier. Processing it is considered too risky.